
讨论班 | ESL讨论班、学术交流研讨班、因果推断讨论班(2021/6/14-2021/6/20)
1、讨论班简介
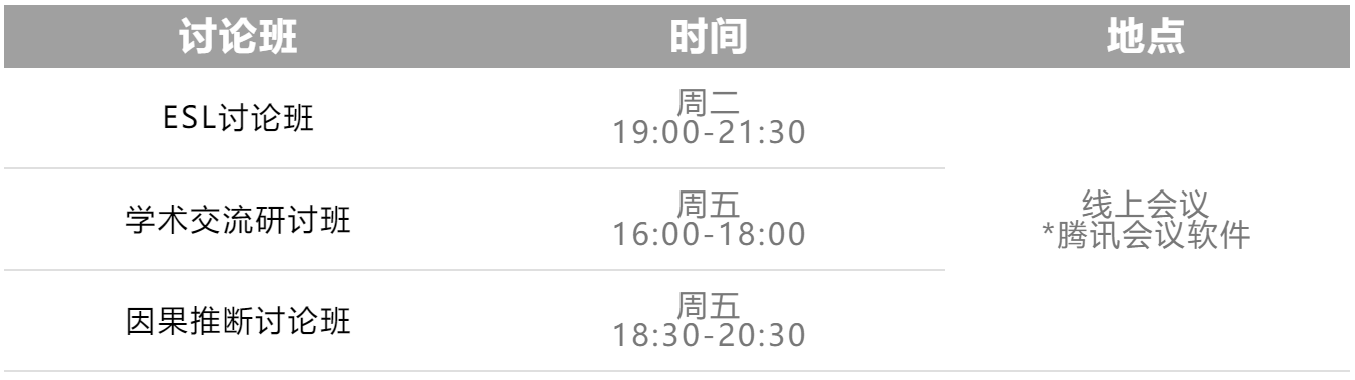
ESL讨论班
针对新同学开展统计学习精要的学习,主讲机器学习知识。课程内容以《The Elements of Statistical Learning》为主,部分延伸内容需要参考辅助书目;
学术交流研讨班
针对博士生开展,主要形式为学术论文讨论交流。
因果推断讨论班
研究主题包括复杂数据的因果推断,精准治疗/决策,IV, DID, RDD, mediation等计量方法,异质性因果效应,因果机器学习,因果网络发现,非参检验,多源数据融合的因果分析和匹配、加权等经典方法的最新进展。
2、时间及地点
3、本期内容概述
ESL讨论班
内容预告
本次我们将讨论无约束条件下的凸优化问题,对于一些经典的算法进行讲解和推导,例如:梯度下降法、最速下降法、牛顿法等方法,这些算法在计算代数领域有着非常深刻的影响。本次课程将从原理上解释无约束凸优化问题的重要算法。
腾讯会议链接
会议主题:ESL讨论班
会议时间:2021/06/08-2021/06/29 19:00-21:30(GMT+08:00) 中国标准时间 - 北京, 每周 (周二)
点击链接入会,或添加至会议列表:
https://meeting.tencent.com/s/lK0zAsGa2lby
会议 ID:432 5678 9554
学术交流研讨班
内容预告
An Introduction of Functional Principal Component Analysis
With the development of social media, a bunch of functional type data, e.g. curves, surfaces, or anything else varying over a continuum, are increasingly used in real-world data analysis. As a generalization of multivariate statistics, functional data analysis focuses on the signal extraction based upon the functional data object, which is usually assumed to be the infinite-dimensional Hilbertian random elements, hence possessing certain difficulty on the statistical learning procedure. In this lecture, we will introduce a fundamental tool for functional data analysis dealling with the infinite-dimensional issue: functional principal component analysis (fpca). The Karhunen-Loève theory and the practical implementation of fpca would be presented and discussed in detail. Moreover, to tackle more theoretically and practically challenging situations like functional time series, we would introduce a concept called separability to adjust the statistical efficiency of fpca. A new framework for the dependent functional data is also proposed to promote the generalized application of fpca.
腾讯会议链接
会议主题:学术交流研讨班
会议时间:2021/05/28-2021/08/27 16:00-18:00(GMT+08:00) 中国标准时间 - 北京, 每周 (周五)
点击链接入会,或添加至会议列表:
https://meeting.tencent.com/s/vwoS2FR3Lef0
会议 ID:591 2872 1234
因果推断讨论班
内容预告
Triplet Matching for Estimating Causal Effects With Three Treatment Arms: A Comparative Study of Mortality by Trauma Center Level
Abstract
Comparing outcomes across different levels of trauma centers is vital in evaluating regionalized trauma care. With observational data, it is critical to adjust for patient characteristics to render valid causal comparisons. Propensity score matching is a popular method to infer causal relationships in observational studies with two treatment arms. Few studies, however, have used matching designs with more than two groups, due to the complexity of matching algorithms. We fill the gap by developing an iterative matching algorithm for the three-group setting. Our algorithm outperforms the nearest neighbor algorithm and is shown to produce matched samples with total distance no larger than twice the optimal distance. We implement the evidence factors method for binary outcomes, which includes a randomization-based testing strategy and a sensitivity analysis for hidden bias in three-group matched designs. We apply our method to the Nationwide Emergency Department Sample data to compare emergency department mortality among non-trauma, level I, and level II trauma centers. Our tests suggest that the admission to a trauma center has a beneficial effect on mortality, assuming no unmeasured confounding. A sensitivity analysis for hidden bias shows that unmeasured confounders, moderately associated with the type of care received, may change the result qualitatively. Supplementary materials for this article, including a standardized description of the materials available for reproducing the work, are available as an online supplement.
Conditional Distributional Treatment Effect with Kernel Conditional Mean Embeddings and U-Statistic Regression
Abstract
We propose to analyse the conditional distributional treatment effect (CoDiTE), which, in contrast to the more common conditional average treatment effect (CATE), is designed to encode a treatment's distributional aspects beyond the mean. We first introduce a formal definition of the CoDiTE associated with a distance function between probability measures. Then we discuss the CoDiTE associated with the maximum mean discrepancy via kernel conditional mean embeddings, which, coupled with a hypothesis test, tells us whether there is any conditional distributional effect of the treatment. Finally, we investigate what kind of conditional distributional effect the treatment has, both in an exploratory manner via the conditional witness function, and in a quantitative manner via U-statistic regression, generalising the CATE to higher-order moments. Experiments on synthetic, semi-synthetic and real datasets demonstrate the merits of our approach.
腾讯会议链接
会议主题:2021因果推断讨论班
会议时间:2021/06/11-2021/07/23 18:30-20:00(GMT+08:00) 中国标准时间 - 北京, 每周 (周五)
点击链接入会,或添加至会议列表:
https://meeting.tencent.com/s/srrKL94HijwT
会议 ID:674 5622 9494

