
讨论班 | ESL讨论班、学术交流研讨班、因果推断讨论班(2021/5/31-2021/6/6)
为配合并加强新冠疫情防控,近期讨论班均以线上会议形式举行,谢谢!
1、讨论班简介
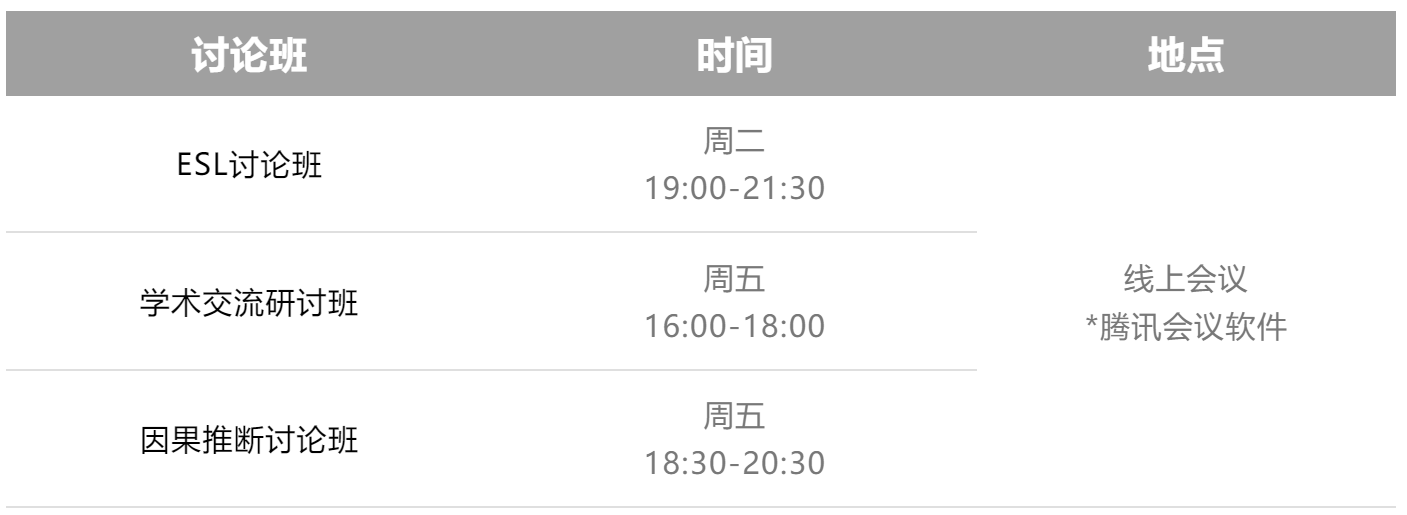
ESL讨论班
针对新同学开展统计学习精要的学习,主讲机器学习知识。课程内容以《The Elements of Statistical Learning》为主,部分延伸内容需要参考辅助书目;
学术交流研讨班
针对博士生开展,主要形式为学术论文讨论交流。
因果推断讨论班
研究主题包括复杂数据的因果推断,精准治疗/决策,IV, DID, RDD, mediation等计量方法,异质性因果效应,因果机器学习,因果网络发现,非参检验,多源数据融合的因果分析和匹配、加权等经典方法的最新进展。
2、时间及地点
3、本期内容概述
ESL讨论班
内容预告
EM(Expectation-Maximum)算法也称期望最大化算法,曾入选“数据挖掘十大算法”中,可见EM算法在机器学习、数据挖掘中的影响力。EM算法是最常见的隐变量估计方法,在机器学习中有极为广泛的用途,例如常被用来学习高斯混合模型(Gaussian mixture model,简称GMM)的参数;隐式马尔科夫算法(HMM)、LDA主题模型的变分推断等等。本次课我们将围绕EM算法展开,讲解EM算法的原理与应用。
腾讯会议链接
会议主题:ESL讨论班
会议时间:2021/06/08-2021/06/29 19:00-21:30(GMT+08:00)
中国标准时间 - 北京, 每周 (周二)
点击链接入会,或添加至会议列表:
https://meeting.tencent.com/s/lK0zAsGa2lby
会议 ID:432 5678 9554
学术交流研讨班
内容预告
Review of Causal Discovery Methods Based on Graphical Models
Abstract:
A fundamental task in various disciplines of science, including biology, is to find underlying causal relations and make use of them. Causal relations can be seen if interventions are properly applied; however, in many cases they are difficult or even impossible to conduct. It is then necessary to discover causal relations by analyzing statistical properties of purely observational data, which is known as causal discovery or causal structure search. This paper aims to give an introduction to and a brief review of the computational methods for causal discovery that were developed in the past three decades, including constraint-based and score-based methods and those based on functional causal models, supplemented by some illustrations and applications.
腾讯会议链接
会议主题:学术交流研讨班
会议时间:2021/06/04 16:00-18:00 (GMT+08:00)
中国标准时间 - 北京
点击链接入会,或添加至会议列表:
https://meeting.tencent.com/s/vwoS2FR3Lef0
会议 ID:591 2872 1234
因果推断讨论班
内容预告
Estimating Average Treatment Effects with Support Vector Machines
Abstract:
Support vector machine (SVM) is one of the most popular classification algorithms in the machine learning literature. We demonstrate that SVM can be used to balance covariates and estimate average causal effects under the unconfoundedness assumption. Specifically, we adapt the SVM classifier as a kernel-based weighting procedure that minimizes the maximum mean discrepancy between the treatment and control groups while simultaneously maximizing effective sample size. We also show that SVM is a continuous relaxation of the quadratic integer program for computing the largest balanced subset, establishing its direct relation to the cardinality matching method. Another important feature of SVM is that the regularization parameter controls the trade-off between covariate balance and effective sample size. As a result, the existing SVM path algorithm can be used to compute the balance-sample size frontier. We characterize the bias of causal effect estimation arising from this trade-off, connecting the proposed SVM procedure to the existing kernel balancing methods. Finally, we conduct simulation and empirical studies to evaluate the performance of the proposed methodology and find that SVM is competitive with the state-of-the-art covariate balancing methods.
Vaccines, contagion, and social networks
Abstract:
Consider the causal effect that one individual's treatment may have on another individual's outcome when the outcome is contagious, with specific application to the effect of vaccination on an infectious disease outcome. The effect of one individual's vaccination on another's outcome can be decomposed into two different causal effects, called the "infectiousness" and "contagion" effects. We present identifying assumptions and estimation or testing procedures for infectiousness and contagion effects in two different settings: (1) using data sampled from independent groups of observations, and (2) using data collected from a single interdependent social network. The methods that we propose for social network data require fitting generalized linear models (GLMs). GLMs and other statistical models that require independence across subjects have been used widely to estimate causal effects in social network data, but, because the subjects in networks are presumably not independent, the use of such models is generally invalid, resulting in inference that is expected to be anticonservative. We introduce a way to ensure that GLM residuals are uncorrelated across subjects despite the fact that outcomes are non-independent. This simultaneously demonstrates the possibility of using GLMs and related statistical models for network data and highlights their limitations.
腾讯会议链接
会议主题:因果推断讨论班
会议时间:2021/06/04 18:30-20:30 (GMT+08:00)
中国标准时间 - 北京
点击链接入会,或添加至会议列表:
https://meeting.tencent.com/s/SXcuhdLo6RT6
会议 ID:244 406 623

