
讨论班 | ESL讨论班、学术交流研讨班、因果推断讨论班(2021/5/17-2021/5/23)
1、讨论班简介
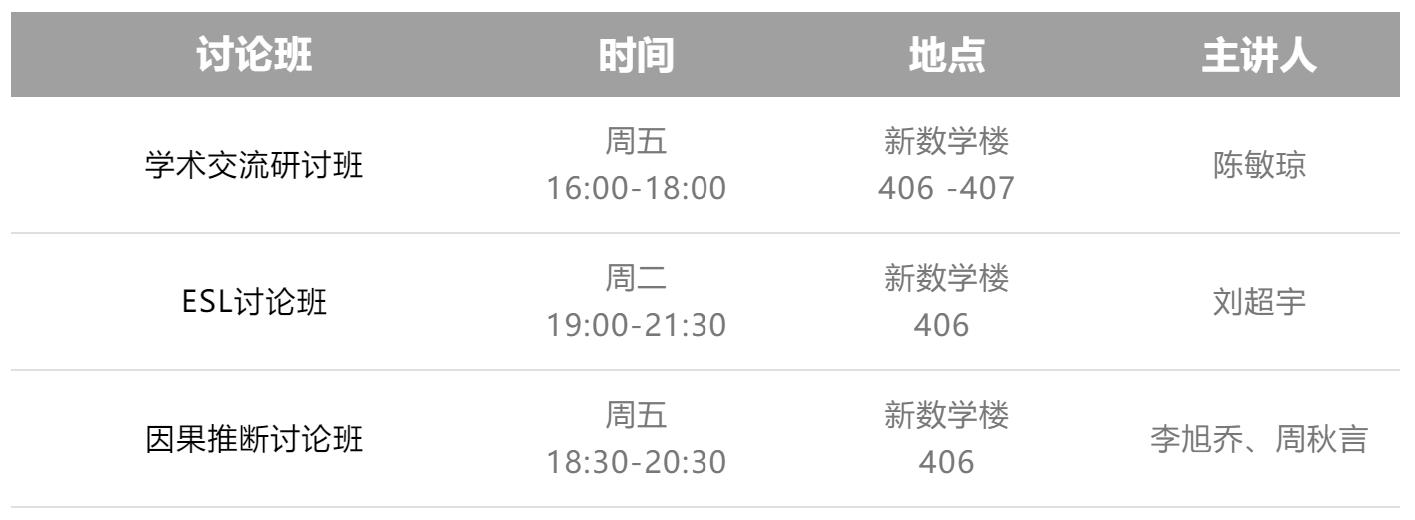
ESL讨论班
针对新同学开展统计学习精要的学习,主讲机器学习知识。课程内容以《The Elements of Statistical Learning》为主,部分延伸内容需要参考辅助书目;
学术交流研讨班
针对博士生开展,主要形式为学术论文讨论交流。
因果推断讨论班
研究主题包括复杂数据的因果推断,精准治疗/决策,IV, DID, RDD, mediation等计量方法,异质性因果效应,因果机器学习,因果网络发现,非参检验,多源数据融合的因果分析和匹配、加权等经典方法的最新进展。
2、时间及地点
3、本期内容概述
ESL讨论班
神经网络(Neural Networks)是一类在统计和人工智能领域分别独立发展但本质上基于相同模型的学习方法,其核心思想是把输入变量的线性组合作为原始的特征,然后根据这些特征建立非线性模型。这是一种强大的学习方法,在许多领域都有广泛的应用。本章我们将首先讨论在半参数统计和平滑领域发展起来的投影寻踪模型,接下来介绍神经网络的基本结构以及如何去拟合神经网络,通过以一个隐藏层的神经网络为例推导拟合神经网络使用的反向传播算法(back-propagation)。此外,还会介绍使用神经网络过程中可能出现的问题以及一些实现案例,最后将简单介绍一下卷积神经网络及其性质。
学术交流研讨班
配对变量分布的差异性比较常见于重复测量或纵向数据的数据分析中,一元配对变量差异比较经典的方法有:配对t检验、Wilcoxon 符号秩检验及针对一些特殊分布类类型,如:威布尔分布的似然比检验法、分类变量的Stuart 检验与0-1变量的McNermar检验。多元情形下配对变量差异比较除了Hotellings’T2 检验之外,较少文献提及。本次讨论班我们首先介绍将Energy distance 用于多元配对数据检验问题的检验统计量,给出相应检验的bootstrap重抽样程序,并证明了bootstrap 方法在逼近原假设分布的合理性;然后将介绍带协变量的配对变量差异检验问题,将Energy distance概念推广到 Conditional energy distance (CED),利用核方法给出相应的估计量并构造检验统计量,同时证明了检验统计量的一致性,及在原假设与备择假设下的渐近正态性。最后进行数值模拟与实例分析,用以展示两种方法的有效性。
因果推断讨论班
FLAME:
A Fast Large-scale Almost Matching Exactly Approach to Causal Inference
Abstract:
A classical problem in causal inference is that of matching, where treatment units need to be matched to control units based on covariate information. In this work, we propose a method that computes high quality almost-exact matches for high-dimensional categorical datasets. This method, called FLAME (Fast Large-scale Almost Matching Exactly), learns a distance metric for matching using a hold-out training data set. In order to perform matching efficiently for large datasets, FLAME leverages techniques that are natural for query processing in the area of database management, and two implementations of FLAME are provided: the first uses SQL queries and the second uses bit-vector techniques. The algorithm starts by constructing matches of the highest quality (exact matches on all covariates), and successively eliminates variables in order to match exactly on as many variables as possible, while still maintaining interpretable high-quality matches and balance between treatment and control groups. We leverage these high quality matches to estimate conditional average treatment effects (CATEs). Our experiments show that FLAME scales to huge datasets with millions of observations where existing state-of-the-art methods fail, and that it achieves significantly better performance than other matching methods.

